[LA] Intermediate Matrices for Inverting Full-Rank Matrix: Cramer's Rule
·
.../Linear Algebra
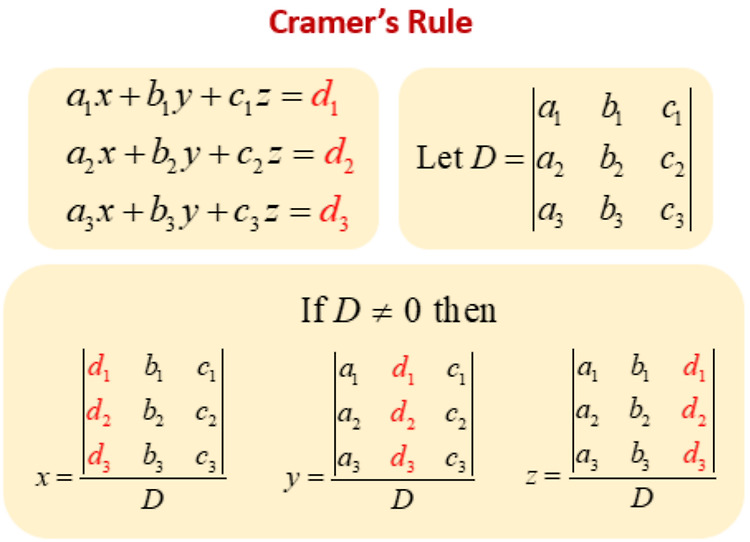
Square Full-Rank Matrix의 Inverse를 Cramer's rule에 기반하여 구하는 방식은 실제 inverse를 구하는 용도로는 많이 사용되지는 않는다.재귀적 방식인지라, 대상이 되는 Square Matrix의 크기가 커질 경우 매우 비효율적이기 때문임.단, 3×3 이하의 작은 크기이거나, Complex Number 로 인해 Row Reduction 등이 효과적이지 못한 경우에는 inverse를 구하는데 사용되기도 함.주요 용도는 Theoretical Tool로서 inverse를 다 구하지 않고도, Ax=b에서 b의 작은 변화가x에 얼마나 영향을 주는지 등을 살피는 것임. 주요행렬이 방식에서 중간..


