Matching에서 geometric alignment와 transform estimation이 중요한 이유는,
단순히 feature vector의 유사도만을 고려하는 것보다 더 신뢰도 높은 대응점을 찾기 위해서임.
Matching 과정에서
- 두 이미지 또는 두 데이터 세트 사이의 correspondence를 찾는 것은 첫 번째 단계에 불과하며,
- 여기서 추가적인 geometric 정보를 활용하면 대응점의 정확도를 크게 향상시킬 수 있음.
때문에 1차적으로 얻은 correpondence를 통해 geometric transform matrix를 구하는 다양한 fitting 기법이 사용됨.
일반적 Matching 과정 절차:
- Feature vector의 distance 계산하여 두 데이터 사이의 잠재적 correspondence 찾기.
- Distance가 작을수록 대응하는 두 feature가 유사하다고 판단.
- 하지만 distance만을 고려한 초기 correspondence들에서는, noise나 잘못된 경우의 포함 가능성 큼.
- 이를 보완하기 위해 geometric transform estimation 필요.
Geometric transform estimation 단계:
- 초기 대응점들로부터 Geometric Transform Matrix(Rigid, Affine, Homography 등)의 파라미터 계산.
- 변환 행렬의 파라미터로 correspondance가 일정한 기하학적 관계를 가지는지를 점검.
변환 행렬 파라미터 활용:
- 초기 correspondence 중 신뢰도가 낮은 점들 걸러냄.
- 더 일관성 있는 correspondence 선택.
- 잘못된 대응 배제 및 의미 있는 대응점들만 남기기.
- 최종적으로 높은 신뢰도의 correspondence 얻기.
- 후속 처리나 분석에서 큰 장점 제공.
1. Matching에서Least Square를 통한 Geometric Transform Matrix구하기
Rigid body인 object에 대한
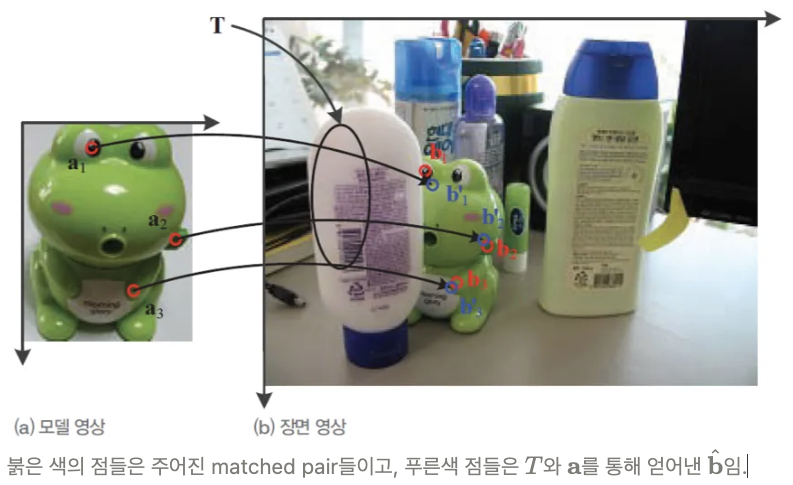
2개의 영상에서의 matched pairs가 다음과 같다고 가정하자.
$$
X=\left\{(\textbf{a}_1,\textbf{b}_1), (\textbf{a}_2,\textbf{b}_2),\cdots, (\textbf{a}_m,\textbf{b}_m)\right\}
$$
모든 matched pair는 같은 geometric transformation($T$)이 이루어졌다고 할 수 있음
(아래의 예는 Affine Transformation임: homogeneous coordinate를 사용함).
$$\begin{aligned}\begin{bmatrix}\hat{b}_1\\\hat{b}_2\\1\end{bmatrix}&=\begin{bmatrix}t_{11} & t_{12} & t_{13} \\ t_{21} & t_{22} &t_{23} \\ 0 & 0 &1\end{bmatrix}\begin{bmatrix}a_1\\a_2\\1\end{bmatrix}\\\hat{\textbf{b}}&=T\textbf{a}\end{aligned}$$
- 이상적으로는 $\hat{\textbf{b}}=\textbf{b}$이지만, 측정치 $\textbf{b}$에는 측정 noise등이 존재할 수 밖에 없어서 $\hat{\textbf{b}}+\textbf{r}=\textbf{b}$가 성립 ($\textbf{r}$ :error or noise or residual).
- $X$ 가 주어진 경우, $\textbf{b}$와 $T\textbf{a}$로 구한 $\hat{\textbf{b}}$간의 에러 $\textbf{r}_1, \textbf{r}_2, \cdots, \textbf{r}_m$이 Gaussian distribution을 따른다고 가정할 경우, least square method로 matrix $T$를 구할 수 있음.
2. Optimization Problem
$$
\hat{\theta}=\underset{\theta}{\text{argmin}}\displaystyle\sum^m_{i=1}||\textbf{r}_i||^2
$$
- $||\mathbf{r}_i||$ : $i$번째 instance의 residual error.
- L2-norm의 특징상 outlier에 취약.
- Outlier의 큰 $||\textbf{r}||$가 매우 큰 영향을 끼침.
- Outlier에 보다 맞춰서 모델의 파라메터 $\theta$가 결정됨.
3. Cost Function
최소화해야할 에러 $E$는 다음과 같음.
$$\begin{aligned} E(T) &= \sum^m_{i=1} ||\textbf{r}_i ||^2\\&=||\hat{\textbf{b}}_i - \textbf{b}_i ||^2\\&=\sum^m_{i=1} \left[ \left\{ b_{1i}-(t_{11}a_{1i}+t_{12}a_{2i}+t_{13})\right\}^2 + \left\{ b_{2i}-(t_{21}a_{1i}+t_{22}a_{2i}+t_{23}) \right\}^2 \right]\end{aligned}$$
위의 $E(T)$를 최소화하는 $T$는 다음의 matrix equation의 solution을 구하면 됨.
$$\begin{bmatrix} \displaystyle \sum_{i=1}^m {a_{1i}}^2 & \displaystyle \sum_{i=1}^m a_{1i}a_{2i} & \displaystyle \sum_{i=1}^m a_{1i} & 0 & 0 & 0 \\ \displaystyle \sum_{i=1}^m a_{1i}a_{2i} & \displaystyle \sum_{i=1}^m {a_{2i}}^2 & \displaystyle \sum_{i=1}^m a_{2i} &0 &0 &0 \\ \displaystyle \sum_{i=1}^m a_{1i} & \displaystyle \sum_{i=1}^m a_{2i} & \displaystyle \sum_{i=1}^m 1 & 0 & 0 & 0\\0&0&0& \displaystyle \sum_{i=1}^m {a_{1i}}^2 & \displaystyle \sum_{i=1}^m a_{1i}a_{2i} & \displaystyle \sum_{i=1}^m a_{1i}\\ 0& 0& 0 & \displaystyle \sum_{i=1}^m a_{1i}a_{2i} & \displaystyle \sum_{i=1}^m {a_{2i}}^2 & \displaystyle \sum_{i=1}^m a_{2i} \\ 0& 0& 0& \displaystyle \sum_{i=1}^m a_{1i} & \displaystyle \sum_{i=1}^m a_{2i} & \displaystyle \sum_{i=1}^m 1\end{bmatrix}\begin{bmatrix}t_{11} \\ t_{12} \\ t_{13} \\ t_{21} \\t_{22} \\t_{23} \end{bmatrix}=\begin{bmatrix} \displaystyle \sum_{i=1}^m a_{1i}b_{1i}\\ \displaystyle \sum_{i=1}^m a_{2i}b_{1i}\\ \displaystyle \sum_{i=1}^m b_{1i}\\ \displaystyle \sum_{i=1}^m a_{1i}b_{2i}\\ \displaystyle \sum_{i=1}^m a_{2i}b_{2i}\\ \displaystyle \sum_{i=1}^m b_{2i} \end{bmatrix}$$
아래 그림과 같이 3개의 matched pair가 주어질 경우, 위의 식을 풀어 $T$를 구함.
4. 단점: 정규분포가 아닌 Noise에 의한 Outlier에 취약
다음은 선형문제에서 outlier에 얼마나 Least Square가 취약한지를 보여주는 예임.
아래 그림에서처럼 $\textbf{x}_5$와 같은 outlier가 있을 경우, $l_2$로 잘못된 solution을 얻게됨
(아래 그림은 선형 문제로 영상 매칭은 아니지만, 2D로 확장되어도 마찬가지임.)

5. Outlier에 보다 robust한 fitting methods.
Least Square Method의 단점(outlier에 취약 = Break point가 0%임)을 극복한 다른 방법들은 다음과 같음:
이들 모두 일종의 regression 방법임.
2024.11.25 - [Programming/DIP] - [Math] Maximum Likelihood Estimator: M-Estimator
[Math] Maximum Likelihood Estimator: M-Estimator
1. M-Estimator란M- Estimator는 Noise 에 Rubust 한 Statistical Estimator(통계적추정방법) 의 하나로서,Maximum Likelihood Estimatro (MLE)를 일반화한 방법임.이는 모델 parameter $\boldsymbol{\theta}$를 추정하기 위해residual $\
dsaint31.tistory.com
2024.11.16 - [Programming/DIP] - [CV] Least-Median of Squares Estimation (LMedS)
[CV] Least-Median of Squares Estimation (LMedS)
Least-Median of Squares (LMedS) 추정법P. J. Rousseeuw가 제안한 강건 회귀 분석 (robust regression) 기법.LMedS는 이상치(outliers)에 대해 매우 강인한 특성을 가짐: 데이터 내 Outlier(이상치)의 비율이 매우 높을 때
dsaint31.tistory.com
2024.06.13 - [Programming/ML] - [ML] RANdom SAmple Consensus (RANSAC)
[ML] RANdom SAmple Consensus (RANSAC)
1. 정의 및 Key IdeaRANSAC (RANdom SAmple Consensus)는 많은 수의 이상치(outlier)가 있는 dataset에서도model의 parameters를 강건하게 추정하는 voting based iteration algorithm.Consensus 합의라는 의미를 가짐. RANSAC의 핵
dsaint31.tistory.com
참고자료
2024.06.13 - [Programming/DIP] - [CV] Fitting
[CV] Fitting
computer vision과 image processing에서의 Fitting목표computer vision과 image processing에서 Fitting의 주요 목표는관찰된 데이터(이미지, 텍스트, 센서 데이터 등)로부터특정 양이나 구조를가장 잘 설명하는 모델
dsaint31.tistory.com
2024.07.17 - [.../Physics] - [Physics] Rigid Body (강체)
[Physics] Rigid Body (강체)
Rigid body(강체)란힘을 가해도 그 모양이 변하지 않는 물체로구성요소가 고정되어 있어서 형태의 변화 (scale도 유지) 없이회전이나 이동할 수 있는 물체.예: 공중으로 던져진 망치(rigidbody)의 운동"
dsaint31.tistory.com
2022.04.28 - [Programming/ML] - [Fitting] Ordinary Least Squares : OLS, 최소자승법
[Fitting] Ordinary Least Squares : OLS, 최소자승법
Ordinary Least Squares : OLS, 최소자승법Solution을 구할 수 없는 Over-determined system에서 solution의 근사치(approximation)을 구할 수 있게 해주는 방법임.Machine Learning에서 Supervised Learning의 대표적인 task인 Re
dsaint31.tistory.com
2024.06.22 - [Programming/ML] - [Fitting] Total Least Square Regression
[Fitting] Total Least Square Regression
Total Least Squares (TLS) RegressionTotal Least Squares (TLS) 회귀는 데이터의 모든 방향에서의 오차를 최소화하는 회귀 방법임.이는 특히 독립 변수와 종속 변수 모두에 오차가 포함되어 있는 경우에 유용함.
dsaint31.tistory.com
'Programming > DIP' 카테고리의 다른 글
| [DIP] Nearest Neighbor Search: Locality Sensitive Hashing (0) | 2024.11.26 |
|---|---|
| [DIP] Matching Strategies and Performance Evaluation (0) | 2024.11.26 |
| [Math] Maximum Likelihood Estimator: M-Estimator (0) | 2024.11.25 |
| [OpenCV] K-Means Tree Hyper-parameters: FLANN based Matcher (1) | 2024.11.25 |
| [DIP] K-Means Tree: Nearest Neighbor Search (0) | 2024.11.25 |