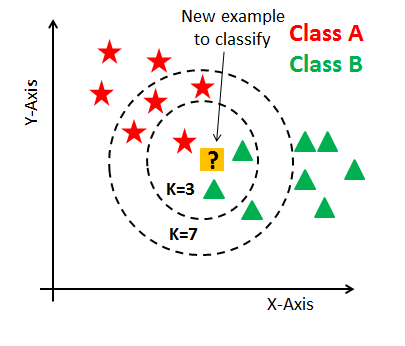
k-Nearest Neighbors (kNN) Classifier는
- Supervised Learning에 기반한
- non-parametric(비모수) 및
- instance-based Algorithm.
이는 Label 이 지정된 data와의 distance를 이용하여 새로운 data point가 어느 class에 속하는지 예측하는 방식.
1. 기본 아이디어:
- 새로운 데이터가 주어졌을 때,
- 해당 데이터와 가장 가까운 k개의 이웃 데이터 포인트 (Nearest Neighbors)를 찾고,
- 이웃들의 Majority Voting(=hard voting) 또는 거리로 가중치를 둔 Soft Voting에 의해 새로운 데이터의 클래스를 결정.
k 값은 사용자가 지정하는 hyper-parameter이며
- 작은 k값은 과적합(overfitting)을 초래할 수 있고,
- 큰 k값은 계산이 복잡해지며 성능이 떨어질 수 있음.
2. 동작 방식:
- 거리 측정:
- 새로운 데이터와 기존 데이터 간의 distance (or similarity)를 계산함.
- 일반적으로 Euclidean distance가 사용되지만,
- Manhattan distance나
- Cosine similarity와 같은
- 다른 distnace functions (or similarity measures)도 사용될 수 있음.
- k Neighbors 선택:
- 가장 가까운 k개의 이웃 데이터를 선택함.
- Voting:
- 선택된 Neighbors 중에서
- 가장 빈번한 클래스를 새로운 데이터의 클래스로 예측함(hard voting).
2024.10.02 - [Programming/ML] - [ML] Minkowski Distance (L-p Norm)
[ML] Minkowski Distance (L-p Norm)
Minkowski 거리는L-p Norm의 한 형태두 개의 점 사이의 distance(거리)를 일반화한 metric.distance의 개념은 다음 접은 글을 참고:더보기https://dsaint31.me/mkdocs_site/DIP/cv2/etc/dip_metrics/#distance-function-or-metric BME228
dsaint31.tistory.com
3. Non-parametric model의 특성:
kNN은 non-parametric model(비모수 모델)임.
- 사전에 학습된 모델이나 고정된 매개변수를 사용하지 않음.
- 모든 training set의 data points를 저장한 상태에서 예측 시점에 distance를 계산하여 prediction을 수행.
때문에 사전에 parameter의 수가 정해지지 않음: non-parametric model이란 사전에 parameters의 수가 정해지지 않는 경우를 지칭.
이로 인해 훈련 데이터가 많아질수록
매우 큰 complexity의 model이 된다.
4. Instance-based algorithm의 특성:
kNN은 Instance-based algorithm임.
- 새로운 data point가 주어졌을 때마다 training set의 data points와 비교하여 예측을 수행함.
- 별도의 학습 과정이 없으며, training set을 그대로 사용(저장)하여 예측을 진행
- 이같은 이유로 lazy learning 이라고도 불림.
kNN은 예측 단계에서 많은 계산이 필요함.
https://dsaint31.me/mkdocs_site/ML/ch00/ch00_31_instance_based_learning/
BME228
Instance based Learning ML의 learning system에서 generalization을 training dataset 그 자체로 구현하는 경우를 instance based learning이라고 한다. 어떤 일반화된 model 이나 function을 구하는 대신에, similarity 혹은 distanc
dsaint31.me
5. 장점:
- 간단함: 수학적 모델링이 필요 없이 직관적이고 구현이 쉬움.
- 적응성: 데이터가 추가될 때마다 쉽게 모델에 반영할 수 있음.
- 비모수적 특성: 데이터의 분포나 구조에 대한 가정이 없으므로 다양한 데이터셋에 유연하게 적용 가능함.
6. 단점:
- 계산 비용: 훈련 데이터가 많아질수록 예측할 때 계산 비용이 매우 커짐.
- 메모리 사용: 모든 훈련 데이터를 저장해야 하므로 메모리 사용량이 큼.
- 고차원 데이터에서의 성능 저하: 차원의 저주(curse of dimensionality) 문제로 인해 고차원 데이터에서는 성능이 크게 저하될 수 있음.
- k 값과 거리 함수 선택의 중요성: k 값과 distance function에 따라 성능이 달라지기 때문에 적절한 파라미터 선택이 중요함.
참고: k-Nearest Neighbors Regression
k개의 가까운 이웃들의 y값을 평균내거나 가중평균하여 연속값을 예측
입력 변수 x가 있고, 출력 변수 y가 있을 경우,
새 샘플 x_new가 들어오면 다음 순서로 동작함:
- 학습 데이터의 모든 샘플과 x_new 의 거리를 계산
- 가장 가까운 k개 샘플 선택
- 그 샘플들의 $y_i$값을 평균 또는 가중평균
- 그 값을 최종 예측값으로 사용
$$\hat{y}(x_\text{new}) = \frac{1}{k} \underset{i\in N_k(x)}{\sum} y_i$$
- $\hat{y}(x_\text{new})$: 입력 $x_\text{new}$에서의 예측값
- $N_k$: $x_\text{new}$에 가장 가까운 $k$개 이웃의 집합(neighbors)
- $y_i$: 각 이웃의 target value.
https://dsaint31.me/mkdocs_site/ML/ch01/ch01_41/#0-k-nearest-neighbors-regressor-knn
BME
bagging boosting ensemble machine learning random forest regression scikit-learn support vector machine [ML] Classic Regressor (Summary) DeepLearning 계열을 제외한 Regressor 모델들을 간단하게 정리함. 분류 Instance Based Algorithm Mod
dsaint31.me
같이 보면 좋은 자료들
https://gist.github.com/dsaint31x/5be040238dde49e67a8b644bb799bc18
ml_knn_classifier.ipynb
ml_knn_classifier.ipynb. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
'Programming > ML' 카테고리의 다른 글
| [ML] Diabetes Dataset (0) | 2024.10.05 |
|---|---|
| [ML] Yeast Dataset (0) | 2024.10.05 |
| [ML] Imputation (0) | 2024.10.05 |
| [ML] scikit-learn: FunctionTransformer (0) | 2024.10.03 |
| [ML] scikit-learn: Pipeline 사용법 (0) | 2024.10.03 |