
Averaged Stochastic Gradient Descent Weight-Dropped 3-Layer LSTM (AWD 3-Layer LSTM) 의 구조를 사용.
상단의 learning rate에 대한 그래프들이 좌/우로 있는데,
- 왼쪽은 layerindex $l$이 증가(upstream layer)할수록 학습률이 큼(Discrimitive Learning Rate)을 의미하고
- 오른쪽은 학습이 진행($t$가 증가)될수록 학습률이 초기엔 증가하다 뒤로가면 감소(slanted triangular learning alogrithm)를 의미.
Layer 의 명암 그라디에션은 gradual unfreezing을 의미함 (백색의 layer들은 첨부터 freeze되지 않고 학습됨).
ULMFiT 란?
ULMFiT (Universal Language Model Fine-tuning)은
자연어 처리(Natural Language Processing) 분야에서
전이학습(Transfer Learning)이 실질적으로 효과적임을 처음으로 명확히 입증한 연구.
ULMFiT은 구조가 아니라 학습 전략의 전환을 통해
현대 자연어 처리 모델의 기반을 마련한 연구이다.
Universal Language Model Fine-tuning for Text Classification, Jeremy Howard, Sebastian Ruder, 2018
Universal Language Model Fine-tuning for Text Classification
Inductive transfer learning has greatly impacted computer vision, but existing approaches in NLP still require task-specific modifications and training from scratch. We propose Universal Language Model Fine-tuning (ULMFiT), an effective transfer learning m
arxiv.org
- 이후 등장하는 Transformer 계열 모델의 학습 패러다임에 중요한 영향을 미침.
ULMFiT의 기본 개념
ULMFiT은
- 대규모 말뭉치(corpus)로
- 사전학습(pretraining)된 언어모델(Language Model)을 기반으로,
- 새로운 문제에 맞게 단계적으로 미세조정(fine-tuning)하는 방법임.
이는 이미지 처리 분야에서
- ImageNet으로 사전학습된 합성곱 신경망(Convolutional Neural Network)을
- 새로운 분류 문제에 맞게 fine-tuning하는 방식과 개념적으로 동일하다.
이미지에서 transfer learning은 다음을 참고: https://dsaint31.me/mkdocs_site/ML/ch11_training/knowledge_transfer/
BME
Transfer Learning The application of skills, knowledge, and/or attitudes that were learned in one situation to another learning situation. (Perkins, 1992) 다른 학습 상황에 배운 기술, 지식 및/또는 태도를 적용하는 것. (퍼킨스, 1992
dsaint31.me
ULMFiT의 3단계 학습 구조

ULMFiT은 다음의 세 단계 학습 과정으로 구성됨:
- 일반 언어모델 사전학습
(General Language Model Pretraining) - 도메인 특화 언어모델 미세조정
(Domain-specific Language Model Fine-tuning) - 과제 특화 미세조정
(Task-specific Fine-tuning)
참고: Language Modeling의 정의
1,2 번 과정에서 사용되는 Language Modeling(언어 모델링)이란 다음과 같이 정의된다.
- 자연어(Natural Language)에서
- 단어(word) 또는 토큰(token)들의 순서(sequence)에 대해
- 해당 시퀀스가 나타날 확률(probability)을 모델링하는 과제(task)
이를 보다 구체적으로 표현하면,
- 이전까지 관측된 단어들이 주어졌을 때,
- 다음 단어가 등장할 확률을 예측하는 문제
라고 할 수 있다
1단계: General Language Model Pretraining
이 단계의 목적은 범용적인 언어 표현(Language Representation)을 학습하는 것임.
- 위키피디아(Wikipedia)와 같은 대규모 일반 텍스트 사용
- 문장의 다음 단어를 예측하는 언어모델 학습
- 문법(grammar), 의미(semantics), 문맥(context)을 포괄적으로 학습
이 단계에서는 다음과 같은 기법을 적용하지 않음.
- Gradual Unfreezing (점진적 레이어 해제)
- Discriminative Learning Rates (레이어별 차등 학습률)
- Slanted Triangular Learning Rate (기울어진 삼각형 학습률 스케줄)
이는 보호해야 할 기존 지식이 없으며,
장기적이고 안정적인 표현 학습이 목적이기 때문임.
2단계: Domain-specific Language Model Fine-tuning
이 단계의 목적은
이미 학습된 언어모델을 특정 도메인(domain)의 언어 분포에 적응시키는 것임..
- 의료 문서, 리뷰 텍스트 등 도메인 특화 데이터 사용
- 여전히 “다음 단어 예측”이라는 동일한 언어모델 과제 유지
- 모델의 역할은 변하지 않음
이 단계에서는 다음 기법들이 선택적으로 사용될 수 있음.
- Gradual Unfreezing (점진적 레이어 해제)
- Discriminative Learning Rates (레이어별 차등 학습률)
- Slanted Triangular Learning Rate (기울어진 삼각형 학습률 스케줄)
일반적으로는 낮은 학습률(learning rate)로 전체 모델을 미세조정하는 것만으로도 충분한 경우가 많음.
이 단계는 언어 지식을 새로 배우는 단계라기보다,
기존 지식의 분포를 특정 domain에 맞게 조정하는 단계로 이해할 수 있음.
3단계: Task-specific Fine-tuning
이 단계는 ULMFiT의 핵심 단계 임.
- 언어모델 위에 분류기(classifier)를 추가
- 감성 분류(sentiment classification), 문서 분류(document classification) 등 최종 과제 수행
- 데이터 수가 적고 과제가 변경됨
ULMFiT 를 설명할 때 Task로 classification이 사용되는 이유는 다음과 같음.
classification은
당시 자연어 처리에서 대표적인 downstream task였고
소량 데이터 환경에서의 성능 향상을 명확히 보여주기 쉬운 task임.
transfer learning의 효과를 직관적으로 비교 가능한 task이다 보니 많이 사용됨.
다른 task가 안되는 건 아님.
이 단계에서 pretraining으로 얻은 기존 언어 지식(language knowledge)이 손상될 위험이 커지며,
이를 방지하기 위해 ULMFiT은 다음의 세 가지 핵심 기법을 제안한다.
1. Gradual Unfreezing
(점진적 레이어 해제)
- 처음에는 classifier (=head)만 학습
- 이후 상위 레이어부터 순차적으로 학습 허용
- 마지막으로 하위 레이어까지 미세조정
이 방법은
- 언어의 기본 구조를 담당하는 하위 레이어를 보호하는 데 목적이 있다.
2. Discriminative Learning Rates
(레이어별 차등 학습률)
- 하위 레이어: 매우 작은 학습률
- 상위 레이어 및 분류기: 상대적으로 큰 학습률
이를 통해
- 기본적인 언어 표현은 유지하면서
- 과제에 필요한 표현만 빠르게 현재 데이터 셋에 적응시킴.
3. Slanted Triangular Learning Rate
(기울어진 삼각형 학습률 스케줄) : slanted 는 그래프 등에서 비대칭인 형태를 의미.
- 학습 초반: 학습률을 빠르게 증가
- 학습 후반: 학습률을 점진적으로 감소
이 스케줄은
- 초기 빠른 적응과
- 후반 안정적 수렴을 동시에 달성하기 위한 기법임.
$$\eta_t = \begin{cases} \eta_{\min} + \frac{t}{\text{cut_fraction} \cdot T} (\eta_{\max} - \eta_{\min}) & \text{if } t < \text{cut_fraction} \cdot T \\ \eta_{\min} + \frac{T - t}{(1 - \text{cut_fraction}) \cdot T} (\eta_{\max} - \eta_{\min}) & \text{otherwise} \end{cases}$$
- $\eta_t$ : Learning rate at time, $t = \text{current_epoch} \times \text{batches_per_epoch} + \text{current_batch_index}$
- $\eta_{\min}$ : Minimum learning rate. e.g. : $\frac{1}{32} \eta_{\max}$
- $\eta_{\max}$ : Maximum learning rate. e.g. : 0.01
- $T$ : 총 반복횟수 (Total number of iterations = # of epoch * iterations per batch )
- epochs = 10, training dataset size = 1000, batch size = 32 : $T=10\times \frac{1000}{32}\approx 313$
- $\text{cut_fraction}$ : Fraction of iterations for increasing learning rate. e.g.: 0.1
ULMFiT과 Transformer 모델의 관계
Transformer 구조(Attention-based Architecture)가
- 2018년 자연어 처리의 중심으로 자리 잡기 시작하였고,
- 당시 대표적인 예가 BERT (Bidirectional Encoder Representations from Transformers), GPT-1 (Improving Language Understanding by Generative Pre-Training) 였음.
ULMFiT은 Transformer 구조를 제안하지는 않았으나,
- 사전학습(pretraining)과 미세조정(fine-tuning)을 통해
- NLP에서 Knowledge transfer (=transfer leanring)이라는 학습 패러다임을 정립함.
이는 그대로 Transformer 계열 모델에 계승됨.
- ULMFiT: 언어모델 사전학습 후 fine-tuning
- BERT: Transformer 인코더 사전학습 후 fine-tuning
- 문장을 “읽고 이해”하기 위한 모델: 문장 전체를 양방향으로 이해하는 데 특화
- Encoder-only Transformer
- GPT-1: Transformer 디코더 사전학습 후 fine-tuning
- 문장을 “한 단어씩 생성”하기 위한 모델: 이전 단어들을 바탕으로 다음 단어를 순차적으로 생성하는 데 특화
- Decoder-only Transformer
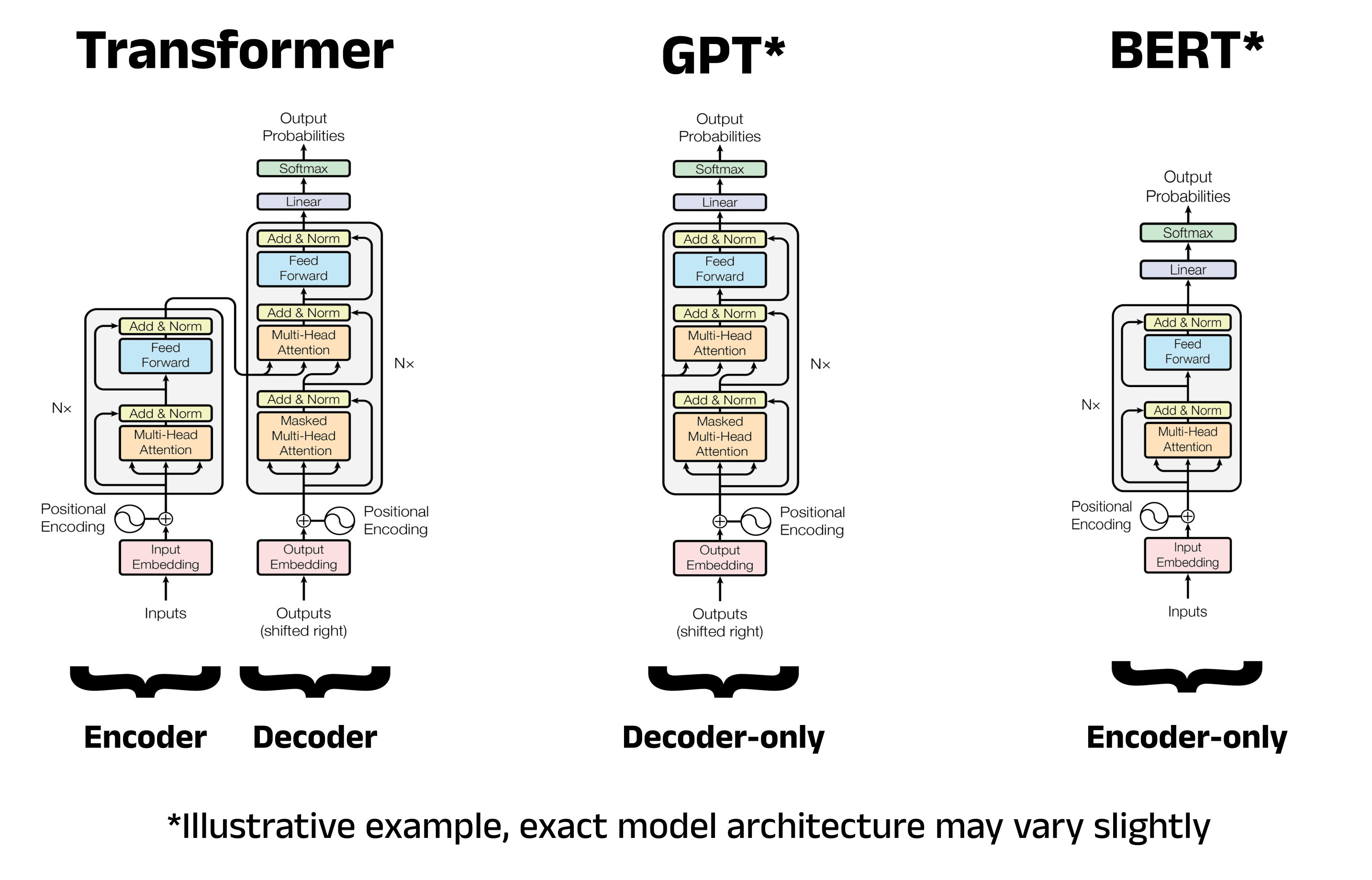
실제로 Transformer 모델 성공의 기반은
- Attention 과
- ULMFiT
라고 애기하는 경우가 많음.
주의할 점:
- ULMFiT은 순환 신경망(Recurrent Neural Network), 특히 LSTM 기반 으로 시작됨.
- Transformer는 자기주의(Self-Attention) 기반 구조
- Transformer는 LSTM 에 비해 보다 구조적으로 안정적이어서
ULMFiT에서 제안한 세부 fine-tuning 기법을 단순화하여 사용
ULMFit 은 “대규모 사전학습 모델을 downstream task에 맞게 조정한다”는 핵심 사고방식 을 자연어 처리 모델 훈련에 적용시킴.
https://dsaint31.me/mkdocs_site/ML/ch16_RNN/RNN_intro
BME
Recurrent Neural Network (순환신경망, RNN) time series data와 같은 sequential data를 다루는데 적합한 ANN. feedback connection을 가짐. 때문에 weight를 구분하여 가지는 layer들이 쌓이기도 하지만, feedback connection에
dsaint31.me
같이 보면 좋은 자료
https://ds31x.github.io/wiki/hf_transformer/hf_post_transformer/
Language Model Taxonomy - Pretraining Paradigms and Encoder-Decoder Architectures
ds31x.github.io
'Programming > ML' 카테고리의 다른 글
| XAI: Coefficient, Feature importance, and SHAP (0) | 2026.03.24 |
|---|---|
| Overfitting (과적합) (0) | 2025.11.20 |
| Lasso Regression (0) | 2025.11.08 |
| Ridge Regression (1) | 2025.11.06 |
| Subgradient 와 Gradient Descent (0) | 2025.11.02 |