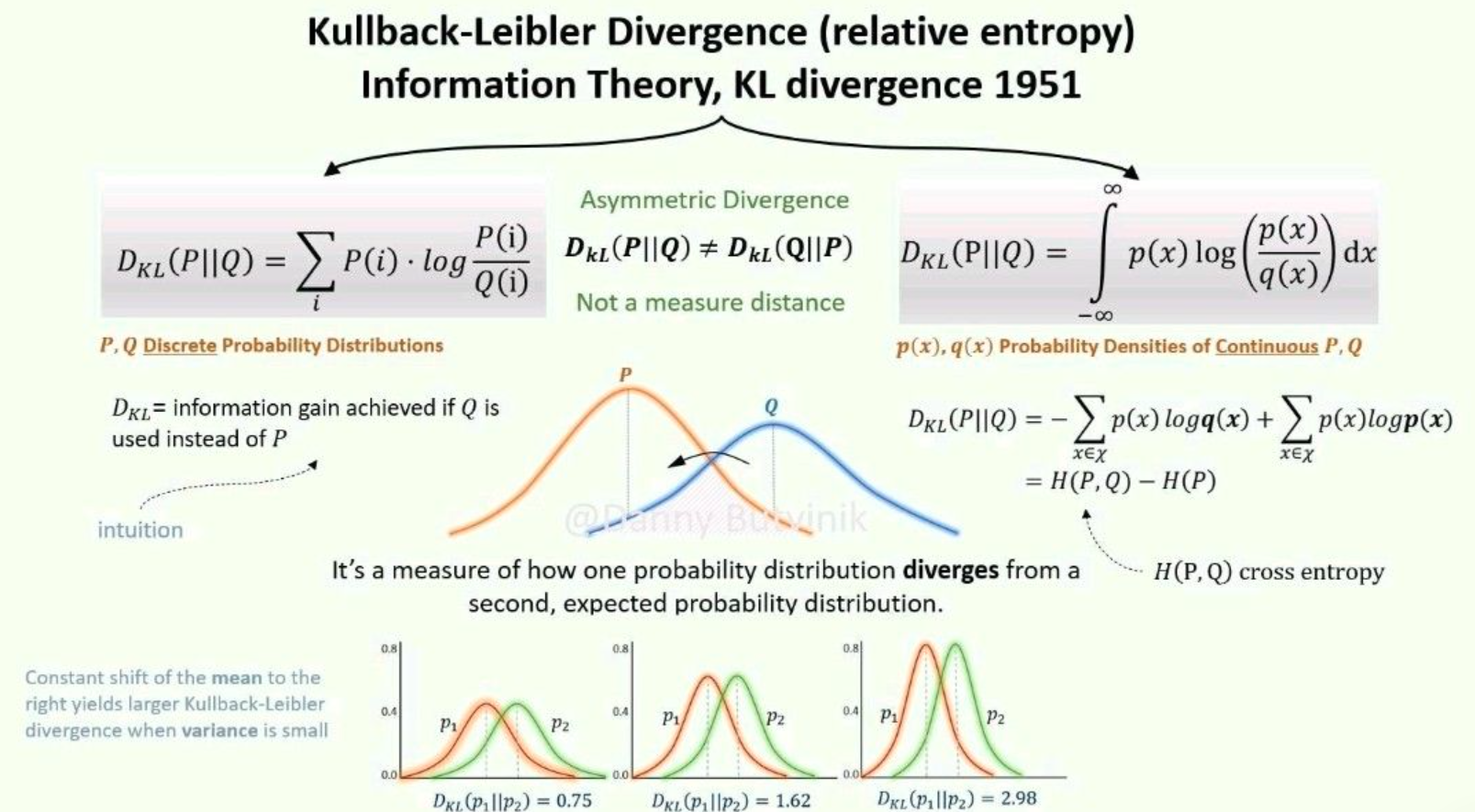
어떤 random variable $x$ (확률변수 $x$)에 대해 원래의 Probability Distribution $p(x)$와 Predicted Probability Distribution $q(x)$ (or Approximated Probability Distribution)가 있을 때, 각 경우의 entropy에 대한 difference가 바로 KL-Divergence임.
Kullback-Leibler Divergence의 정의식은 다음과 같음.
$$\begin{aligned}D_{KL}(p||q)&=\sum^N_{i=1}p(x_i)\left(\log{p(x_i)}-\log{q(x_i)}\right)\\&=\left(-\sum^N_{i=1}p(x_i)\log{q(x_i)}\right) - \left(-\sum^N_{i=1}p(x_i)\log{p(x_i)}\right)\\&=\text{Cross_Entropy}-\text{Entropy}\end{aligned}$$
where
- $p$ : original probability distribution (or ideal probability distribution). 우리가 예측하거나 맞추고자 하는 대상.
- $q$ : 우리가 학습 또는 측정 데이터로부터 예측한 probability distribution. 추정치
- $N$ : random variable $x$가 가질 수 있는 값의 종류.
- $p(x_i)$ : random variable $x$가 $x_i$를 값으로 가질 실제 확률.
- $q(x_i)$ : random variable $x$가 $x_i$를 값으로 가질 확률에 대한 추정치. 현재 우리가 측정 데이터 혹은 학습데이터로부터 예측해낸 추정치를 의미.
직관적으로는 두 확률분포가 얼마나 겹치는지와 반비례하는 것이 KL Divergence라고 볼 수 있음:
P와 Q의 상대적인 log ratio를 가중합으로 보는 것이나
직관적으로보면 확률분포가 얼마나 겹치는지를 대략적으로 보여주는 지표(반비례하게)임.
위의 Kullback-Leibler Divergence의 정의식에서 알 수 있듯이, $p(x)$와 $q(x)$ 의 Cross entropy 에서 $p(x)$의 entropy (p의 정보량을 부호화하는데 필요한 최소한의 bit수에 해당)를 뺀 값이다.
Cross entropy가 원래 $p(x)$의 확률분포인 $x$를 확률분포 $q(x)$로 추정한 경우 얻어지는 entropy이므로, 여기서 확률분포 $p(x)$를 따르는 $x$가 가진 원래 entropy를 빼 줄 경우, 정보량의 측면에서 보면 다른(or 차이가 있는, 에러가 있는) 확률분포 $q(x)$를 사용할 경우 요구되는 추가적인 정보량이 구해지며, 이것이 KL-Divergence에 해당한다.
- 참고 : 2022.05.12 - [분류 전체보기] - [Math] : Cross Entropy
- 참고 : 2022.05.12 - [.../Math] - [Math] Entropy 란 (평균정보량, 정보량의 기댓값)
결국, 두 확률분포간의 dissimilarity(차이점, 같지않은 정도)에 해당하는 quantity라고 할 수 있다.
정보량이 클 경우 encoding에 요구되는 code길이가 늘어나는데, entropy는 실제로 해당 확률변수를 encoding하는데 이론적으로 필요한 code의 최소 평균길이에 해당한다. 즉, 차이가 있는 확률분포($q(x)$)를 기반으로 확률변수 $x$를 인코딩할 경우 추가적인 평균길이를 갖는 code가 필요하고, KL-Divergence는 추가되는 정도를 나타냄.
기계학습이나 딥러닝의 알고리즘을 통해 우리가 만들어낸 모델은, 학습 데이터(or 측정 데이터)로부터 얻은 일종의 확률분포 추정치($q(x)$)로서 실제 우리가 맞추고자 하는 확률분포($p(x)$, supervised learning의 경우 label데이터에 의해 결정됨)와 차이가 있으며, 해당 차이를 KL-Divergence가 정량화하여 나타낸다고 할 수 있다.
확률분포간의 거리(distance) metric으로 사용가능한가?
주의할 점은 위의 설명에서 분포간의 차이점(dissimilarity)이라는 부분을 강조했을 뿐, KL-Divergence가 두 확률분포 간의 거리(distance)라고 하지 않았다는 점이다. KL-Divergence는 일종의 이항연산이며, 피연산자로 두 개의 확률분포가 주어진다. 문제는 이 피연산자의 순서가 바뀔 경우, KL-Divergence의 결과값이 달라지는 non symmetric 특성을 가지고 있기 때문에 distance는 되지 못한다.
기계학습 최적화 등에서 사용사례
두 확률분포 간의 dissmiilarity를 정량화하며, 비슷할수록 값이 줄어드는 특징을 가지므로 현재 학습 모델이 학습 데이터에서를 얼마나 잘 반영하는지를 나타내는 loss function (or cost function)으로 사용가능하다.
하지만 일반적으로 KL-Divergence보다는 Cross Entropy가 보다 많이 사용된다.
그 이유는 KL-Divergence 정의식에서도 알 수 있듯이 Cross Entropy에서 Entropy를 뺀 값이 KL-Divergence인데, Entropy는 학습데이터(Label포함)가 정해질 경우 같이 정해지는 값으로 학습기간 중에 학습데이터를 교체하지 않는 한 constant(상수)에 해당한다. 즉, 굳이 cost function에 상수값을 매번 빼주는 연산을 추가할 필요가 없다. 더욱이, 모델의 파라메터에 대한 gradient를 구할 때, 상수에 대한 편미분들은 결국 0이니 이 같은 경우엔 KL-Divergence가 Cross-entropy만으로 충분하다.
References
https://www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained
Kullback-Leibler Divergence Explained — Count Bayesie
Kullback–Leibler divergence is a very useful way to measure the difference between two probability distributions. In this post we'll go over a simple example to help you better grasp this interesting tool from information theory.
www.countbayesie.com
http://colah.github.io/posts/2015-09-Visual-Information/
Visual Information Theory -- colah's blog
Posted on October 14, 2015 <!-- by colah --> I love the feeling of having a new way to think about the world. I especially love when there’s some vague idea that gets formalized into a concrete concept. Information theory is a prime example of this. Info
colah.github.io
'... > Math' 카테고리의 다른 글
| [Math] Entropy 란 (평균정보량, 정보량의 기댓값) (0) | 2022.05.12 |
|---|---|
| [Math] Cross Entropy (0) | 2022.05.12 |
| [Math] Matrix Calculus : Numerator Layout (0) | 2022.05.08 |
| [Math] Jacobian : Summary (0) | 2022.05.07 |
| [Math] Commonly used Vector derivatives. (0) | 2022.05.05 |